

The cloud interruptions last year were on rage. Numerous cloud services ceased working at various points. Social networking websites and home management software both encountered downtime. Apps and websites that are entirely cloud-based also experienced outages. These problems, as well as others, were inevitable when most employees began telecommuting.
Despite incidents like these, corporations kept moving workloads to the cloud. Businesses’ appetite for the cloud has dramatically increased over the past two years. Most companies use public cloud services. According to Laminar, the rapid technological change and sloppy security procedures have escalated data breaches.
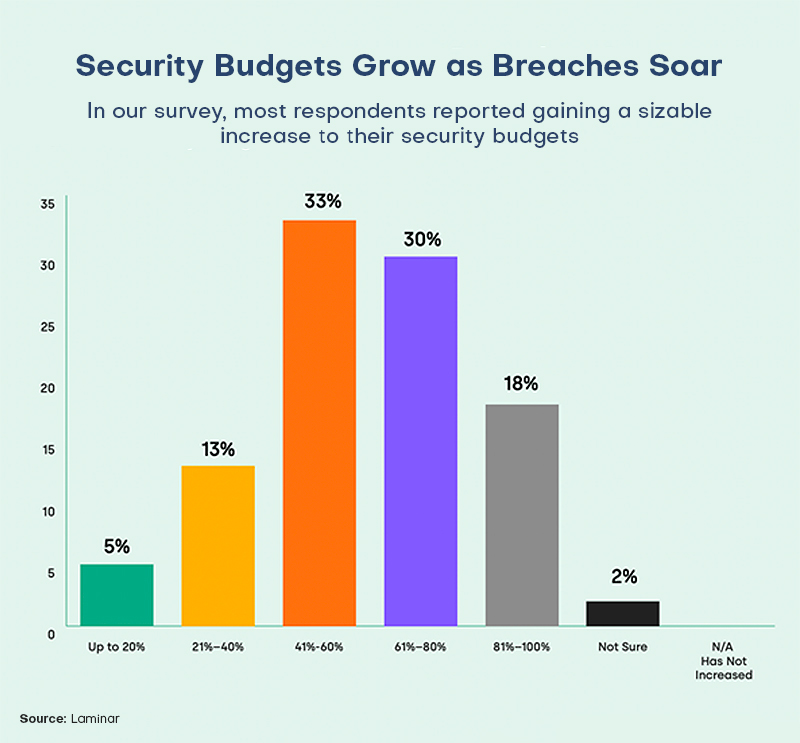
According to the poll, more than 50% of security experts acknowledged that their organization was attacked in 2020 or 2021. And a whopping 58% of people who were victims of the cyberattacks claimed they were unable to regain lost data.
Is a Cloud Disaster Recovery Strategy the Way?
Perhaps the virtual nature of the cloud is what makes it invincible. But this is a widespread misconception. Data is stored on actual servers even when accessed through the cloud. Virtual machines operate similarly. The security of data kept in the cloud has been threatened by server failure, calamities, and even cyberattacks. So what can be done to secure the cloud?
Here is where a cloud disaster recovery plan comes into play. Data might be lost permanently if a well-planned CDR strategy is not there. Companies should immediately activate a CDR plan and use the tactics listed below while creating it to create a cloud environment free from fallacies. Before that, get familiar with CDR.
What is a CDR?
Disaster recovery, also abbreviated as Cloud DR, is a strategy set up in case of an emergency. Disaster recovery plans are designed to swiftly enable access to critical systems and IT infrastructure after a disaster. In order to be ready for this, businesses typically do a thorough analysis of their infrastructure and create a formal document (DR) to follow in a crisis. Thus, cloud disaster recovery plans are procedures and approaches that guarantee an organization’s flawless functioning with the help of utilizing the super features provided by the cloud partner.
Securing the Data in the Cloud – Best CDR Practices
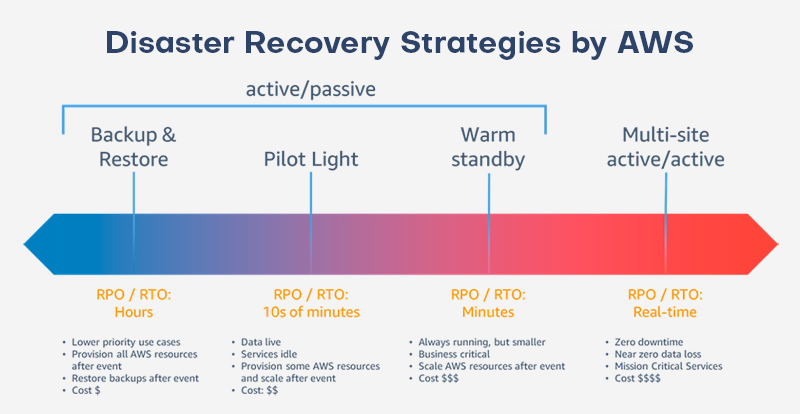
Cloud recovery options the AWS way
There are four major categories of disaster recovery techniques that you may use in AWS, ranging from simple backup systems with little cost and complexity to more intricate plans utilizing many active Regions. Active/passive techniques host the workload and serve traffic from an active location (like an AWS Region). A passive location (such as a different AWS Region) is for recovery utilized. The passive site does not proactively handle traffic until a fallback event occurs.
In order to feel confident using your disaster recovery plan, it is essential to evaluate and test it constantly. Utilize AWS Resilience Hub to continually assess and monitor the resilience of your AWS workloads, such as the probability that you will achieve your RTO and RPO goals.
Consider logical steps
Most companies jump from 0 to 100mph when attempting to transfer apps and data. This results in an excessive number of moving components and insufficient time for error correction. Your big relocation operation will consequently fail, at least to some degree. Act systematically rather. Create a thorough strategy, spend the effort to arrange the apps in the proper priority order, and afterward move the data and applications in batches.
Whether you are performing a straightforward “lift and shift” sort of migration or a thorough redesign of the apps and the data, use logical strategy.
Identify infrastructure and threats
Do your research prior to moving ahead. Analyze the infrastructure of the business, its resources, and its information. This will highlight perils that can hurt the company’s crucial resources and data. After assessing the risks, create strategies for reducing these potential dangers. After listing the risks, develop a robust disaster recovery strategy. This can aid in defending your cloud infrastructure from potential dangers.
Additionally, DR is useful in times of crisis to manage the situation well. Risk assessment is a continuous process, not a one-time event. A company’s risk analysis guidelines must be continuously updated if its architecture changes.
Make a business analysis
Risks come in a wide range of forms and dimensions. A critical program may become inoperable due to an event; a cloud data breach brought on by anyone keeping encryption keys in their possession, or an unexpected data loss. Any successful cloud disaster recovery strategy must include a business impact analysis or BIA. It seeks to pinpoint any possible ramifications that may interrupt business activities. The organizational impact study emphasizes the outcomes of specific workflow disruptions more than the reasons and likelihoods behind them.
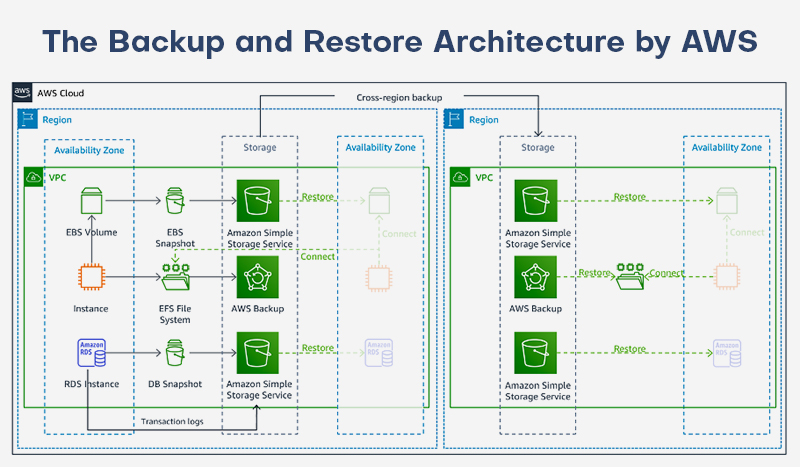
Backup and restore
Data loss or corruption may be mitigated with backup and restoration. Suppose you are using AWS cloud services. Duplicate data to additional AWS Regions. This strategy can be used to overcome the lack of redundancy for workloads allocated to a specific Availability Zone or to address a regional disaster. In the recovery Region, you must also reinstall the architecture, configuration, and application code in addition to the data. Always use infrastructure as code (IaC) when deploying infrastructure so that it can be easily and error-free transferred using tools like AWS Cloud Formation or the AWS Cloud Development Kit (CDK). Without IaC, restoring workloads in the recovery Region may be difficult, which would lengthen recovery durations and perhaps cause them to surpass your RTO (recovery time objective).
The DR plan should be based on RPO and RTO.
RPO and RTO play a crucial role in drafting the company’s disaster recovery plan. These procedures aid firms in carrying on uninterrupted commercial operations. RTO measures how soon a business can restart operations or recover from a crisis, while RPO (recovery point objective) is concerned with assessing the amount of data acceptable for a corporation to lose in the event of system breakdown. RTO also ensures that recovery and disaster mitigation procedures are in order. Consequently, integrating RTO and RPO can make it easier to select an event management strategy that can support businesses in achieving recovery goals.
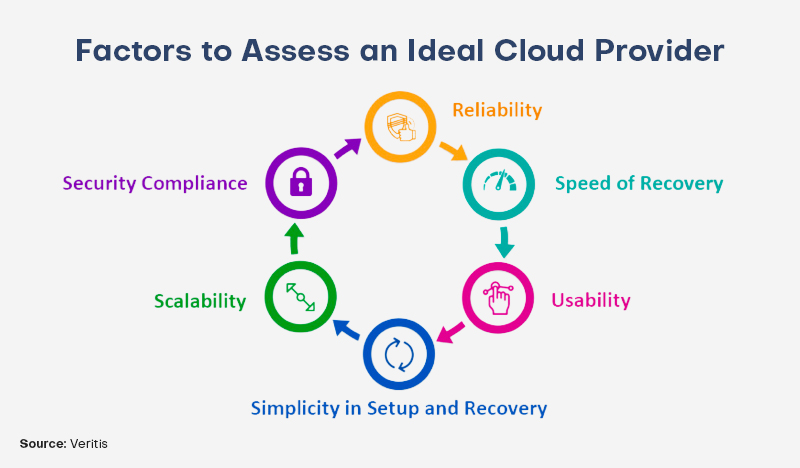
Opting for the right cloud partner
After developing a realistic and effective disaster plan, selecting a trustworthy cloud service provider is important to help with the deployment. Before selecting the best partner for your company’s needs, look at a few variables if comprehensive duplication in the cloud is required. These elements include protection, configuration and backup solutions that are easy to use, dependability, and recovery period.
There are a number of logistical considerations depending on the DR strategy you choose:
- How many different parts of the infrastructure will you need?
- What optimal security and compliance standards must you set up?
- Process of data migration
- What are the effective methods for managing user access and authentication?
- What safeguards will you use to lessen the possibility of mishaps?
Just don’t forget that successful company operations depend on your DR plan being in line with your RTO and RPO requirements.
Evaluating and revising the cloud-based DR strategy
It’s essential to review if the plan truly works in the event of a disaster when it has been fully developed, and individuals have been given tasks. Make sure that a catastrophe never occurs and if it does, organization should be prepared to handle. It implies that the strategy must be properly and regularly tested. Frequent updates should also be made, and the rollout of those changes has to be constantly monitored.